本文共 3597 字,大约阅读时间需要 11 分钟。
陈师哲同学在“多模态情感识别”和“视频内容自然语言描述”研究方面取得了突出的研究成果,在领域顶级会议和期刊发表论文十余篇,并在多项高水平学术竞赛中取得优异成绩,表现出很强的科研能力、实践动手能力和科研潜力。
王云鹤在神经网络加速压缩方面做了深入研究。他提出利用离散余弦变换将卷积神经网络预测过程中的卷积计算从空间域转换为频率域,在准确度只有轻微下降的前提下,预测速度大幅度提升、模型消耗的存储大幅度降低。该方法极具创新性和实用性。
陈师哲:人民大学

人大信息学院直博三年级的学生,导师是金琴老师。我的研究方向是多媒体计算,通过多模态的语义分析实现更加和谐自然的人机交互,主要分为两个方面:
1)客观语义分析:根据视频内容生成自然语言描述(video captioning),客观地理解多模态视频中的物体/动作/关系等等;
2)情感语义分析:多模态情感识别和理解(multimodal affective computing),通过不同模态分析人物的情感状态从而更好地与人类交互。
阶段性研究成果介绍:
1)视频内容的自然语言描述生成(video captioning)
视频内容的自然语言描述生成(video captioning)的研究目标是为视频内容生成自然语言描述,这是视频语义内容理解的最高目标之一。这一研究具有非常广泛的应用价值,例如帮助视力有障碍的人群理解认识周围的世界;更好地对互联网视频进行索引、存储、分析和推荐,使得用户能够更好地浏览、选择、搜索视频内容等等。
目前图片内容描述的自动生成(image captioning)已经取得了非常显著的进步,但是和imagecaptioning相比,video captioning这一研究更为挑战,主要的难点包括:
A. 多模态:视频包含多种模态信息,例如视觉/声音/文本等等。为全面准确理解视频内容,我们提取了多模态特征,提出多模态融合模型有效利用融合多模态。
B. 时序性:物体或事件的时间发展顺序影响着对视频内容的理解。因此,我们采用了时序模型和时序注意力机制对视频的时序特性进行建模。
C. 主题广:视频的主题跨度非常广泛,不同主题下,多模态融合策略和语言描述空间有较大差异。因此,我们提出隐含主题指导模型,自动挖掘视频中的隐含主题,利用这些主题指导生成更准确和细节的描述。
我们的视频内容描述模型在2016-2017年连续2年获得了在国际多媒体顶级会议ACM Multimedia上由微软组织的视频内容描述挑战赛MSR-VTT的冠军,和2017年NISTTRECVID上举办的国际视频内容描述冠军。
2)多模态情感识别(multimodal emotion recognition)
理解人类的情感是构建自然的人机交互非常重要的一步。这一研究在服务/教育/娱乐/医业等不同产业都有着非常广泛的应用,例如通过对用户的自动情感识别改善自动服务中对用户的交互方式等等。
我们的研究主要致力于情感识别的两大基本模型:离散情感识别和维度情感识别。主要的技术难点包括:
A. 情感特征构建:人的情感是通过不同的模态信息反映的,包括面部表情/肢体动作/语音语调/说话内容/生理信号等等。因此,我们基于信号处理和深度学习等方法从不同的模态中提取情感区分力显著的情感特征。
B. 多模态情感特征融合:不同模态特征在不同场合情形下的可信度和情感表现力是不同的。 因此,我们提出了条件注意力模型动态地进行多模态情感特征融合。
C. 时序性:人的情感状态是动态变化的,且非常具有时序依赖性。因此,我们提出了动态时序模型进行连续的维度情感识别。
与导师相处轶事:
1)治学严谨:从金老师身上我感受到的是一个学者严谨务实的态度。例如,在我最初论文写作的过程中,她会跟我反复斟酌论文的逻辑框架,每一个公式都会严谨地推算,每一个词都会细细地推敲。当时距离论文截止日期非常近,我们就连续十多个小时在办公室里讨论和修改,最终呈现出令人满意的工作。
2)工作投入:金老师对待工作热情投入的态度给我极大的鼓舞。平时,我经常收到金老师在凌晨3、4点的工作邮件;去开会的旅途中,大家一般都选择休息闲聊,而金老师却仍然保持着积极的工作状态,阅读钻研前沿论文;即使放假的时候,哪怕是春节等重大节日,金老师也依然会和我们保持紧密的联系,保证科研工作的推进。
3)关心学生:金老师不仅是我在学术研究中的导师,更是我人生生涯中的良师。有一次在论文死线前压力大想放弃的时候,她没有苛责我,而是非常温柔地告诫我说放弃是很简单一件事,并不会有有特别严重的后果,但是很多事情的机会就只有一次,错过了就不能重来,为什么不激励自己坚持做完不留遗憾呢。
金老师在生活上也非常关心我。这次出国以后,有次和老师不经意聊天提到一件在国外不好买的东西,结果之后一起参加学术会议时她竟然就从国内带过来送给我了。更让我感动的是,即使在科研一线、百忙之中,金老师每年都会给学生发去生日祝福。
王云鹤:北京大学

学智能科学系2013级直博研究生,我在神经网络加速压缩方面做了深入研究,提出利用离散余弦变换将卷积神经网络预测过程中的卷积计算从空间域转换为频率域,在准确度只有轻微下降的前提下,预测速度大幅度提升、模型消耗的存储大幅度降低。该方法极具创新性和实用性。
深度卷积神经网络压缩这个课题非常具有应用前景,因为深度学习模型在大多数任务(例如图像识别、图像超分辨率等)上的精度已经达到了落地需求,但是它们的线上速度和内存消耗还没有达到落地需求。
深度卷积神经网络已经在计算机视觉上得到了广泛的应用,例如图像分类、人脸验证等。然而,大多数的卷积神经网络难以被应用在移动端设备上。例如,利用AlexNet或VGGNet对一张图片进行处理需要消耗超过232MB的内存以及数十亿次的浮点数乘法计算。因此,如何压缩并且加速这些复杂的卷积神经网络是非常重要的一个研究课题。
为了解决上述问题,我的研究提出利用离散余弦变换(DCT)在频域上对卷积神经网络进行压缩与加速。卷积核被看做小尺度的光滑图像块,每个卷积核在频域上的表示被分解为共有部分和私有部分的和;共有部分用来指代每个卷积核与其他卷积核相似的方面,而私有部分用来指代其独特的信息。
这两个部分都可以通过舍弃大量微弱系数来实现压缩和加速的目的。在标准数据集上的实验证实了本研究所提出的算法要优于其它算法。
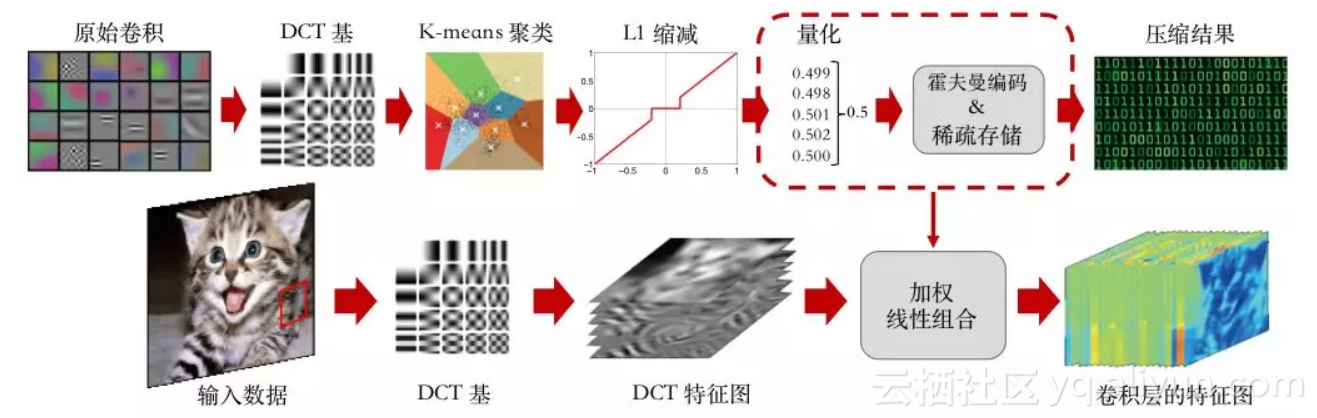
图1: CNNpack算法流程图
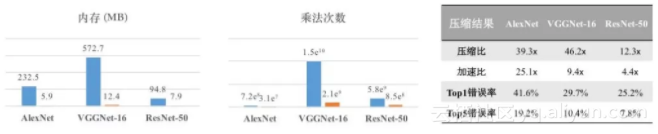
图2: CNNpack算法的压缩结果
深度卷积神经网络压缩这个课题非常具有应用前景,因为深度学习模型在大多数任务(例如图像识别、图像超分辨率等)上的精度已经达到了落地需求,但是它们的线上速度和内存消耗还没有达到落地需求。然而,越来越多的实际应用需要用到这些深度学习模型,例如手机、智能摄像头、无人车等。所以如何设计更轻便、更高精度的深度神经网络仍旧是一个亟需解决的问题。
很幸运在读博期间能有两个指导老师,第一个是北京大学的许超老师,印象最深刻的一句话是“磨刀不误砍柴工”,曾经在一个小的数据集上跑检索实验需要半个小时,优化代码后只需要两分钟,从此走向了一个略有强迫症性质的coding之路。许超老师给人的感觉很平和,正如他微信号的签名一样,“上善若水”,有次ddl前生病了,许老师说“生病了就好好休息,会议还有很多,我们去投下一个”,泪目。
另外一位是悉尼大学的陶大程老师,陶老师经常给予我非常大的鼓励,印象最深刻的一句话是“anyway,云鹤,我觉得你这个idea,very smart”哈哈。陶老师是一个在学术上非常严谨,成果非常多,业内知名的华人学者。最佩服的品质还是敬业,按道理,一个某种程度上来说功成名就的人,对每一个学生的每篇论文都认真修改。有时候自己读了几遍都没发现的错别字和语法错误都会被陶老师发现并作出修改。并且陶老师每天的工作时间超越了他的所有学生。
读博最大的收获就是提出了CNNpack算法,发表在NIPS2016上,并于海思合作,第一次体会到了学术上的算法可以受到工业界的关注。期间最大的困难在于深度学习的模型都需要非常大的计算量和计算资源,所以许超老师购置了新的服务器,并把组内的计算资源都先优先给我使用,非常信任和认可我的工作。同时,结合传统图像压缩和视频压缩的算法,给出了很重要的算法上的意见。
此外,现有的方法大多数都是在图像分类的实验上进行验证的,例如VGGNet,ResNet等。实际应用中,神经网络的需求是多种多样的,例如语音语义识别、物体分割等。这些模型具有和图像分类神经网络不一样的功能和结构,所以更具体的算法也需要被提出。
原文发布时间为:2018-01-26
本文作者:弗朗西斯
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号
原文链接:
转载地址:http://xgkix.baihongyu.com/